Coyote Quick Start
This is a brief introductory section outlining the steps to run Coyote and the essential prerequisites for its setup.
Prerequisites
Full Vivado/Vitis suite is needed to build hardware designs. Hardware server will be enough for deployment only scenarios. Various Ubuntu versions should be supported (we advise on using 20.04).
Warning
Coyote runs with Vivado 2022.1. Previous versions can be used at one’s own peril.
Following AMD data center cards are supported: Alveo u50, Alveo u55c, Alveo u200, Alveo u250 and Alveo u280. You can also deploy Coyote on a development board, for example vcu118.
Coyote has continously been developed on the HACC cluster at ETH Zurich. For more information and possible external access check out the following link: ETH Zurich HACC.
CMake is used for project creation (version 3.0+) and builds. Additionally Jinja2 template engine for Python is used for some of the code generation.
The API is writen in C++, 17 should suffice (for now).
If networking services are used, to generate the design you will need a valid UltraScale+ Integrated 100G Ethernet Subsystem license set up in Vivado/Vitis.
To run the virtual machines on top of individual vFPGAs the following packages are needed: qemu-kvm, build-essential and kmod.
Initialization
You can clone the full Coyote repository if you want to change stuff within the framework. When cloning the repository be sure to check out all the submodules:
> git clone --recurse-submodules https://github.com/fpgasystems/Coyote
Otherwise, we suggest to use Coyote as a submodule within your projects:
> git submodule add https://github.com/fpgasystems/Coyote
> git submodule update --init --recursive
An example of how this can be done can be seen in the following repo: Coyote-PROJECT.
Building and Loading the Hardware
The CMake is coupled with the project flow within Vivado. This flow provides the capability to synthesize individual application projects (to be loaded in different virtual FPGAs) independently and subsequently merge them into a single overarching project after the synthesis step.
This is the basis for the nested system layers exposed by Coyote. The following sub-layers (each represented by a different Vivado project) exist:
Static Layer : This is the static portion of the system. It is always the same for every project (for the same chip). It provides the bare essential functionality to support the rest of the system.
Dynamic (Shell, Service) Layer : This layer houses all the services offered by Coyote which are shared among all applications. It is the first dynamic layer that can be swapped during runtime and represents the current shell configuration.
Application Layer : This layer houses all user projects, each representing a separate user application. The number of overall projects depends on two factors:
the number of virtual FPGAs (vFPGAs) within the dynamic layer (
N_REGIONS), andthe number of different configurations of these vFPGAs within the overarching shell (
N_CONFIG).
Hardware Configuration
The hardware configuration is provided via CMake. The following is an example of a project configuration:
cmake_minimum_required(VERSION 3.0)
project(example_prj)
set(CYT_DIR ${CMAKE_SOURCE_DIR}/) # Path to Coyote dir
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} ${CYT_DIR}/cmake)
find_package(CoyoteHW REQUIRED)
# Shell configuration
set(FDEV_NAME "u55c") # Link to u55c static
set(N_REGIONS 2) # Number of vFPGAs in this specific shell
set(EN_PR 1) # Enable 2nd level dynamic reconfiguration
set(N_CONFIG 2) # Number of app dynamic configurations
set(EN_STRM 1) # Interface to host memory
set(EN_MEM 1) # Interface to FPGA-side memory (HBM/DRAM)
set(HBM_SPLIT 1) # Specific HBM configuration
validation_checks_hw() # Validate configuration
load_apps ( # Load arbitrary user applications for all configs
VFPGA_C0_0 "<some_path_to_the_cores>/addmul"
VFPGA_C0_1 "<some_path_to_the_cores>/cntmin"
VFPGA_C1_0 "<some_path_to_the_cores>/shifter"
VFPGA_C1_1 "<some_path_to_the_cores>/hloglog"
)
create_hw() # Generate all targets
This project will link to the existing static design floorplanned for the Alveo u55c chip.
After indicating the path to Coyote repository, the shell configuration is chosen. In the example, we enable two distinct vFPGAs.
Each of these functions as an independent hardware process, accommodating one user application (user process) at a time.
Applications in these vFPGAs can also be swapped during runtime without disrupting the surrounding shell operations (EN_PR flag).
Multiple dynamic configurations can be compiled within one project (N_CONFIG).
Additional flags can then be provided. All these will define the exact configuration of the shell.
Note
For the complete list of the shell configuration options please check Shell Configurations.
Be sure to include the validation_checks_hw() and create_hw() functions, necessary for properly setting up the environment.
Project Structure
The load_apps() function facilitates the automatic loading of user hardware applications into the corresponding vFPGAs.
This process also performs any essential high-level synthesis compilations, if needed.
When utilized, users must explicitly provide path to all configurations (N_CONFIG x N_REGIONS).
The hardware applications (in the provided path) should be structured as follows:
├ <coyote submodule>
├ CMakeLists.txt (an example can be the one shown previously)
└ <path_to_your_hw_project>
├ vfpga_top.svh (this is the integration wrapper, connect your stuff to the interfaces)
├ init_ip.tcl (all extra IP cores can be instantiated here, buffers, ILAs, VIOs ...)
└ hls (put all your hls cores under this directory)
├ kernel_1
└ kernel_1 files (should contain kernel_1.cpp top level)
├ kernel_2
└ kernel_3
└ hdl
└ all RTL cores and files that might be used (.v, .sv, .svh, .vhd, ...)
Note
Be sure to create the vfpga_top.svh. This is the main integration header file. It is used to connect your circuits to the interfaces exposed by each vFPGA.
It is not necessary to use the load_apps() function. You can also integrate your circuits manually into the provided wrappers (available after the project creation step).
Builds
The projects can be built after configuration and directories have been setup. First, the build directory can be created:
> mkdir build_hw && cd build_hw
The CMake configuration can then be invoked:
> cmake <path_to_cmake_config> <any_additional_configs_if_needed>
If all validation checks pass without errors, all the necessary build files will be generated after this step. Project creation can be then be invoked with the following command:
> make project
This will create all projects:
<project_name>_static # Only if static region is being generated (BUILD_STATIC = 1)
<project_name>_shell # This is the dynamic shell
<project_name>_config_0/<project_name>_user_c0_0 # (vFPGA_C0_0)
<project_name>_config_0/<project_name>_user_c0_1 # (vFPGA_C0_1)
...
<project_name>_config_1/<project_name>_user_c1_0 # (vFPGA_C1_0)
...
If load_apps() was used, there is nothing else that users need to do after this command.
Otherwise each of the user projects (vFPGA_CX_Y) will contain wrappers under the project/hdl directory where
users can instantiate their circuits as they please.
Compilation
Compilation can then be executed. To generate all bitstreams straight away, users can run:
> make bitgen
The command consists of the following incremental steps:
> make synth # Synth all layers
> make link # Link all layers
> make shell # Compile the shell (static + dynamic layers)
> make app # Compile the application layer (only if EN_PR is enabled)
> make bitgen # Generate all bitstreams
If EN_PR floorplanning of the applications (vFPGAs) needs to be done by users explicitly after the make shell step.
This can be done by opening the generated shell_subdivided.dcp checkpoint.
Check out the following link for the detailed floorplanning guide.
Alternatively, users can provide pre-existing vFPGA floorplanning via the FPLAN_PATH variable during configuration.
Once the (typically quite lengthy) compilation is done, the bitstreams will be generated for each application and configuration. The shell bitstream (the dynamic layer bitstream) with the initial (config 0) configuration will also be generated. This one can be used to load the shell dynamically and swap out other shells during runtime. All of these will be present in the bitstreams directory.
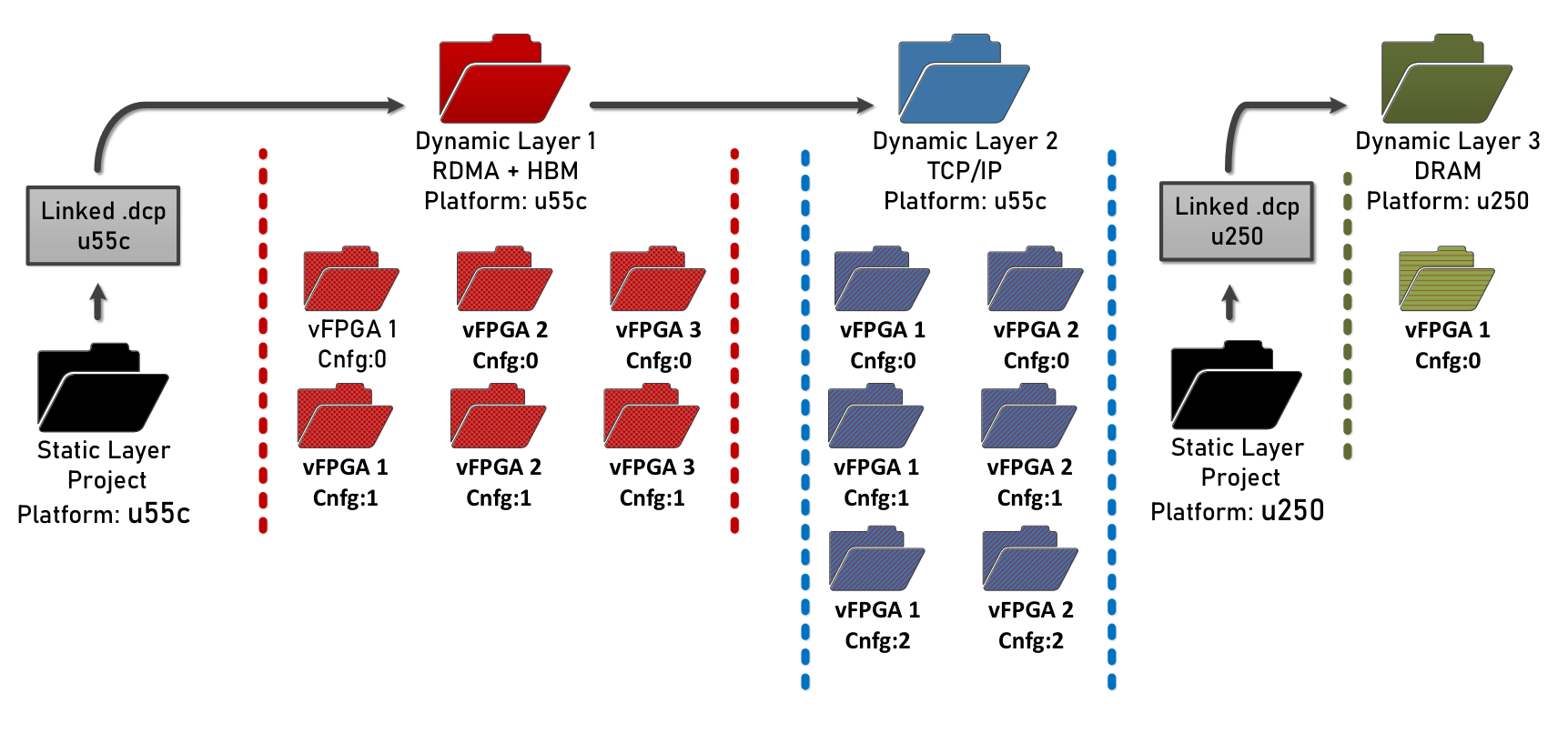
The overall bitstream structure should roughly resemble the one in the figure above.
Linking Additional Projects to the Existing Shell
One advantage of the nested framework organization is that additional user applications can easily be added to already compiled shells.
For instance, an application in a networking shell with RDMA enabled can easily be added without having to resynthesize the complete shell.
To do this, users can create an additional project and link it against an existing shell project. An example of CMake configuration in this case is shown below:
# Shell configuration
set(BUILD_SHELL 0) # We are reusing a shell, not building a new one ...
set(BUILD_APP 1) # App flow, instead of the default shell flow
set(N_CONFIG 2) # Number of additional configurations to be added
set(SHELL_PATH "path_to_the_existing_shell_dir")
validation_checks_hw() # Validate configuration
load_apps ( # Load additional apps
VFPGA_C0_0 "<some_path_to_the_cores>/aes_cbc"
VFPGA_C1_0 "<some_path_to_the_cores>/aes_ecb"
)
create_hw() # Generate all targets
The rest of compilation flow doesn’t differ from the one already covered.
> make project
> make bitgen
After the compilation, additional bitstreams for the newly added applications will be created which can be dynamically swapped within the existing shell.
Loading the bitstreams
The initial bitstreams (static layer) can be loaded via JTAG through Vivado’s hardware programmer. The script under /util/program_alveo.tcl can be used for this loading procedure. All other bitstreams (shell and application bitstreams) are loaded through the Coyote framework and do not require external tools.
Note
Bitstreams with .bin extensions should be used when loading the designs dynamically through Coyote. If bitstreams are being programmed through Vivado programmer, use the ones with .bit extension.
Hot Plug
Whenever the static image of Coyote is loaded for the first time the interconnect has to be rescanned.
For this purpose the scripts under /util/flow_alveo.tcl directory can be used. The ETHZ-HACC cluster contains all the necessary infrastructure to automate this for the end users.
Note
The rescanning needs to be done only for the initial loading of the static shell. Subsequent shells can be loaded dynamically during runtime.
Building and Loading the Driver
The driver can be built by running make within the driver directory:
> cd driver && make
Note
Be sure to compile the driver on the target deployment machine.
Driver Insertion
After compilation you can insert the driver (make sure to have sudo):
> insmod coyote_drv.ko <args>
The following arguments can be supplied during driver insertion:
Argument |
Function |
|---|---|
config_fname |
Configuration file, mapping of devices, used when multiple FPGAs are available. |
cyt_arch |
Target underlining platform. Used to target different interconnects like ECI. |
en_hmm |
Enable heterogeneous memory management. |
en_hypervisor |
Run Coyote in hypervisor mode. Used when running VMs on top of vFPGAs. |
ip/mac_addr |
IP and MAC addresses for the network stacks. |
Exposed vFPGA Devices
Once the driver is inserted a range of device files will be exposed in the kernel under /dev.
These can be used from the user space to access the target devices.
> ls -la /dev/fpga*
fpga_0_v0
fpga_0_v1
...
fpga_0_pr
fpga_1_v0
...
If system contains multiple FPGAs, the first number will indicate the ID of this FPGA.
These IDs can be manually assigned by providing an external config_fname file during driver insertion.
The second number after the v indicates the target vFPGA. Additinoally, the pr device is available which is used by user space scheduler to control the dynamic reconfiguration.
Users can also interact with the system through the sysfs file system. Coyote will expose a number of internal registers
which can be read from and writen to in order to control and debug the live system.
These can typically be found under /cat/sys/kernel/coyote_cnfg.
Building the Software
Procedure to build the software is similar to the one for hardware, albeit more simple.
First create a build directory:
> mkdir build_sw && cd build_sw
Then set the TARGET_DIR in CMake which points to the main sources:
> set(TARGET_DIR "${CYT_DIR}/<some_path_to_sources>")
Additional header files can be included in the path under include. After that you can just run make:
> make
Running Coyote as a Service
Coyote can also be deployed as a background daemon. Check out the example to see how this can be invoked.
Communication with the daemon is done through either the Unix domain sockets or through TCP sockets for local and remote services, respectively.
Shell Loading
User shells (different versions of the dynamic layer) can be loaded at any point as long as the common static layer is on-line.
These can be loaded via the provided examples software application (examples_sw/apps/reconfigure_shell).
Users can also load shells dynamically from within their code via the cRnfg` class.
Similarly applications in the app layer can be loaded via the same class, but additionally the loading can also be
controlled by the derived cSched class which can additionally handle the necessary scheduling.