Features
In this section, we delve into some of the most importand abstractions and features provided by Coyote.
Unified application interface
One of the core goals of Coyote is to make hardware acceleration accessible even for users with little to none FPGA experience, the simplicity of the user interfaces in vFPGAs is a must. The user interface is the sole point of contact between the user-supplied application logic (vFPGA) and the abstraction mechanisms included in Coyote. The interfaces serve as entry and exit points for both data and control flow to and from the vFPGAs. Generally, Coyote exposes the following interfaces to vFPGAs:
axis_host_recv|send: AXI4 Stream interface for receiving/sending data from/to the host memory. The number of parallel streams from host memory to the vFPGA can be determined by the user.axis_card_recv|send: AXI4 Stream interface for receiving/sending data from the FPGA-attached memory (HBM or DDR). The number of parallel streams from the memory to the vFPGA can be determined by the user.cq_rd|wr: Completion queues for reads/writes: a streaming interface to receive completion events for finished transactions that originated in the vFPGA.sq_rd|wr: Send queues for reads/writes: a streaming interface used for defining read and write operations, by specifying the virtual address, length, etc.axi_ctrl: AXI4 Lite interface used for setting control registers within the vFPGA. This allows an interaction between host and vFPGA via PCIe through which the vFPGA becomes the origin of the control flow. The use of this interface is demonstrated in Examples 3 and 7.notify: A stream interface which allows the vFPGA to send notifications to the software program running on the host, leading to an interrupt. Obviously, this is useful for exception handling and system control messages.
Network specific interfaces: if the user specifies a network stack (TCP/IP or RDMA) in the build parameters, the corresponding AXI4 Stream interfaces will be exposed in the vFPGA. For RDMA, these interfaces are:
axis_rreq_send|recv: This interface is used for transporting locally requested data from/to the vFPGA to/from the RDMA stack as payload for outgoing RDMA_WRITE operations.axis_rrsp_send|recv: This interface is used for transporting remotely requested data from/to the vFPGA to/from the RDMA stack as payload for outgoing RDMA_READ_RESPONSE operations.
Similar to the hardware interfaces, Coyote also provides a generic and unified software handle to users, allowing them to efficiently control the vFPGAs from host software.
The core concept here is the Coyote Thread (cThread), which maps to a single vFPGA. As shown in Example 1, data movements can be invoked from such a thread, and the completion of such operations be checked by polling the respective status registers associated with this thread.
Multi-tenancy
One of the key advantages of using Coyote in a datacenter or cloud computing environment is its wide-ranging support for multi-tenancy and multi-threading, allowing to utilize the reconfigurable fabric more efficiently. Multi-tenancy is realized in Coyote in two ways:
Spatial multi-tenancy: Coyote allows for multiple vFPGAs in the application layer. All core system abstractions and services: host interaction via PCIe, access to the card-attached HBM and the networking stack are provided equally to all vFPGAs through sophisticated arbitration and scheduling mechanisms.
Temporal multi-tenancy: Coyote supports partial reconfiguration on the vFPGA level, meaning that single applications residing in vFPGAs can be swapped in and out during run-time. The once configured and built system abstractions can thus be used sequentially by different applications while avoiding the lengthy process of generating a full application-specific bitstream.
Memory
In Coyote, all memory resources, including those on the host system and the FPGA card, are virtualized. This approach abstracts the physical memory details, allowing vFPGAs to access memory seamlessly without direct concern for its physical location. Additionally, virtualized memory is a mechanism for data protection and process isolation, as different vFPGAs can only access their own memory; akin to the virtual memory model in a typical OS. Similar to conventional virtual memory models, Coyote incorporates translation lookaside buffers (TLBs) within its memory management unit (MMU) for efficient virtual-to-physical address look-ups. The TLBs are highly configurable through synthesis parameters and are implemented using on-chip RAM (BRAM), therefore acheiving very fast look-ups.
Coyote facilitates direct access to host memory from the FPGA through the axis_host_recv|send interface.
This capability allows the vFPGA accelerators to directly access host memory, with no intermediate copies to card memory.
On the card, Coyote automatically instantiates the necessary controllers for High Bandwidth Memory (HBM) or Double Data Rate (DDR) memory on the card.
Additionally, Coyote implements striping, ensuring that the data buffer is equally partitioned accorss all the HBM banks, thus maximising bandwidth and reducing pipeline stalls.
This simplifies the development effort, enabling the developers to focus on application implementation and performance tuning.
The data from card memory is through the axis_card_recv|send interface.
Networking
Coyote comes with two different full-fledged networking stacks: 100G TCP/IP and 100G RoCE v2, openning up research possibilities for hardware and systems research alike. Notably, these stacks place the FPGA as an equal-class citizen in the datacenter and enable scale-out accelerated applications. More specifically, Coyote can be used as a basis for building SmartNICs and SmartHubs by offering application offload directly on the network datapaths. For many stream-based data preprocessing tasks, such as ML data pre-processing, such off-loads can significantly improve performance, compared to off-datapath processing, which is available in many commercial SmartNICs and Data Processing Units. Another benefit of Coyote compared to commercial platforms lies in the fact that both of the network stacks are completely open-source and can therefore be customized and modified in new ways to test new concepts of high-performance networking.
GPU integration
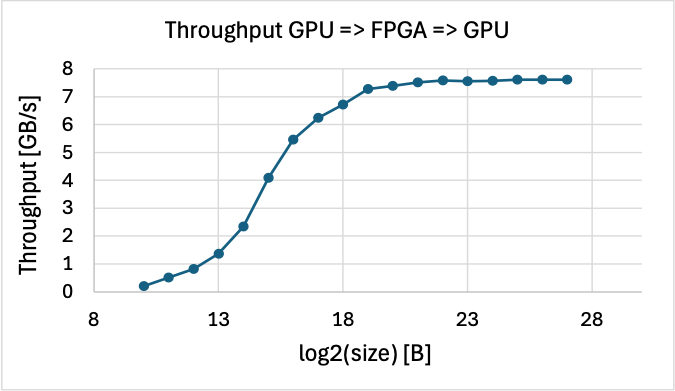
Recognising the importance of heteregenous computing in the era of big data and AI, Coyote aims simplify the integration of FPGAs with other accelerators and NICs. As stated above, Coyote’s RDMA stack is fully RoCEv2-compliant, meaning it can interface directly with off-the-shelf commodity NICs. Additionally, Coyote includes support for DMA with AMD Instinct GPUs, by exporting GPU memory as a DMABuf. By doing so, data transfers between the GPU and FPGA can completely bypass CPU memory, minimising latency and reducing CPU utilization. For more details on how to use Coyote with GPU support, check out Example 6: GPU P2P Below is a figure showcasing the throughput of data movement between a GPU and an FPGA.
Dynamic reconfiguration
Coyote supports two types of reconfiguration: shell and partial (application) reconfiguration. Recall, Coyote’s hardware stack consists of the static layer and the shell (dynamic layer + application layer). The primary purpose of the static layer is facilitate communication and data movement between the host CPU and the FPGA. For the same chip, the static layer always remains the same; that is, it cannot be reconfigured. The shell includes all of Coyote’s services (networking stacks, memory controllers, TLBs etc.) and user applications (vFPGAs).
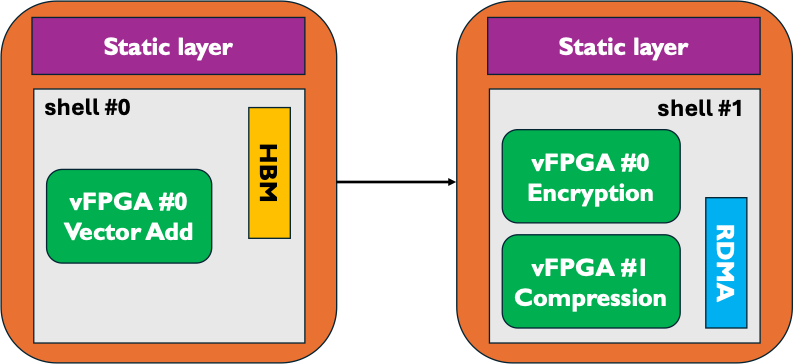
Shell reconfiguration refers to the reconfiguration of the entire shell: both the services (dynamic layer) and the user applications (application layer) are reconfigured. For example, in the figure below, the first shell is built with HBM, no networking and includes one vFPGA for vector addition. The new shell includes no HBM controller, but instead has RDMA enabled with two vFPGAs (encryption, compression). Importantly, the two shells are completely different: the first one has no networking and one user application, the other one includes networking and two user applications. Shell reconfiguration can be done at any time from the software, provided the two shells were linked against the same static layer. For more details on the nuances of shell reconfiguration, see Example 5: Shell reconfiguration.
On the other hand, partial reconfiguration (PR) refers to the reconfiguration of user applications (vFPGAs). The services (networking stacks, memory controllers, TLBs) and the number of vFPGAs stays the same, but the application logic changes. For more details on the nuances of partial reconfiguration, see Example 9: Partial reconfiguration.
Simulation environment
Coyote features a simulation environment that can be used to test the hardware code in the Vivado simulator without having to synthesize the project.
It wraps the vFPGA code in a testbench which simulates host and card memory streams and the corresponding request interfaces and the axi_ctrl and notify interfaces.
The simulation environment may either be used with a Python unit test framework which allows to write unit test for vFPGAs or a simulation target for the Coyote library.
The latter allows the user to compile the software code that they would use to interact with the actual hardware against the simulation.
The networking-related interfaces are currently not supported.
Python run-time
In addition to Coyote’s C++ software API, Coyote also provides a Python run-time, pyCoyote, that exposes the same functionality as the C++ library. This allows users to interact with Coyote from Python, providing a higher level of abstraction as well as integration with popular Python libraries such as NumPy. The Python run-time is built using pybind11, which creates bindings between C++ and Python. The Python run-time supports most of Coyote’s features, including multi-tenancy, data movement, interrupts, and reconfiguration. For more details on how to use the Python run-time, check out the pyCoyote repository. and the corresponding examples.